Reachability Queries
In graph theory, reachability refers to the ability to get from one vertex to another within a graph. A vertex s can reach a vertex t if there exists a path that starts with s and ends with t.
Reachability is one of the most fundamental questions that one can ask about the graph. For example, in a network of papers with edges representing citations, one might ask if one paper is based on another paper, in some possibly indirect way. Even classical algorithms like Dijkstra’s Algorithm can be significantly sped up by avoiding expansion of vertices that cannot reach target vertex.
The advent of massive graph structures comprising of hundreds of millions of vertices and billions of edges can make simple graph operations slow. Due to many applications and expensive computation in classical databases, the reachability problem has obtained much attention in the database community.
Reachability can naively be answered by any graph exploration algorithm (like DFS, BFS) that is zero preprocessing and linear query time. On the other hand, it’s possible to preprocess all possible pairs in quadratic time and answer that is quadratic preprocessing and constant query time.
Additionally, the index data structures must reside in the main memory, creating an upper bound of space consumption.
Trade-offs between preprocessing time, query time, and space requirements make reachability a fascinating problem to analyze. Understanding the nature of the graph involved is crucial in making the right decision.
I have been selected as Google Summer Of Code Student for Git, working on the project Implement Generation Number v2.
Undirected Graphs
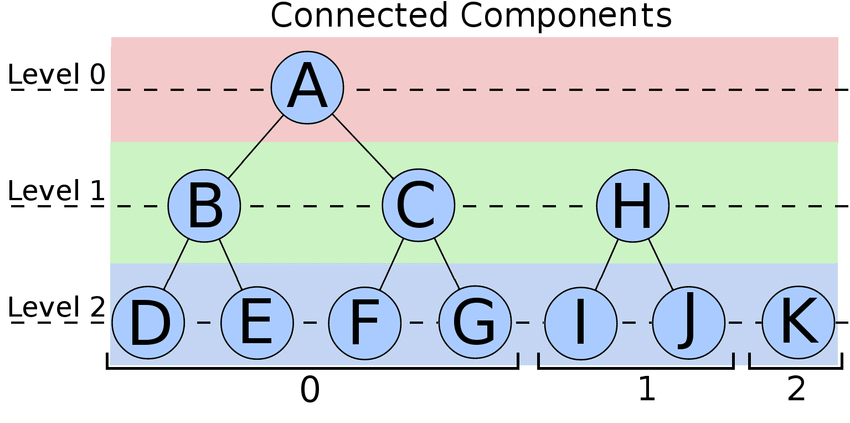
In an undirected graph, reachability is symmetric (s reaches t iff t reaches s). Therefore, reachability between any pair of vertices can be determined by identifying the connected components of the graph.
The connected components of an undirected graph can be identified in linear time Tarjan’s Algorithm or more efficiently by a straightforward application of Disjoint Set Unions.
Both solutions can answer queries in constant time.
Directed Graphs
For directed graphs, reachability is no longer symmetric. However, we can still form Strongly Connected Components i.e., subgraphs where each vertex is reachable from every other vertex of the subgraph.
We can then condense SCCs into “super-vertices”. By definition, this condensed graph would be a Directed Acyclic Graph. It’s important to note that the queries Q(G, u, v) and Q(G’, [u], [v]) are equivalent, where G’ is the condensed graph and [u], [v] are the representative elements of the strongly connected components.
Therefore, one of the preliminary steps before using the algorithms below is to find strongly connected components, which can be done in linear time using Kosaraju’s Algorithm or Tarjan’s Strongly Connected Components Algorithm.
Topological Level
Topological levels for a vertex are defined as follows:
- If the vertex has no incoming edges, it has topological level 0.
- Otherwise, the vertex’s topological level is one more than the maximum of all vertices with incoming edges (usually called a “parent” vertex).
Sometimes, it’s easier to work backward - that is vertices with no outgoing edges are assigned topological level of infinity, and parents have one fewer level.
As it’s easy to see from the image, vertex s can reach vertex t if the topological level of s is greater or equal to that of t. Topological levels can quickly find unreachable vertices, and are examples of “negative-cut filters”.
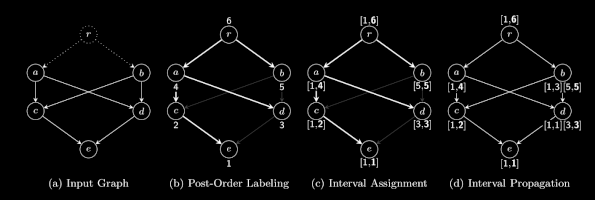
Post Order Interval
The key idea for post-order intervals is to assign each vertex a numeric identifier and represent reachable sets of vertices in a compressed form with an interval.
To assign node identifiers, the tree is traversed in a depth-first manner, visiting in post order. In the figure (b) below, vertex e is visited first and is assigned post order number 1.
Post-order labeling results in identifier locality i.e., for every complete subtree of T form a contiguous sequence of integers. Subtrees of vertex a form the contiguous sequence [1, 4] in figure (c).
However, a node can have multiple parents (like vertex c), we need to propagate the intervals as well - forming figure (d).
To answer a query, we need to check if the post order number of the target is contained in one of the intervals associated with the source. Queries can be answered in logarithmic time.
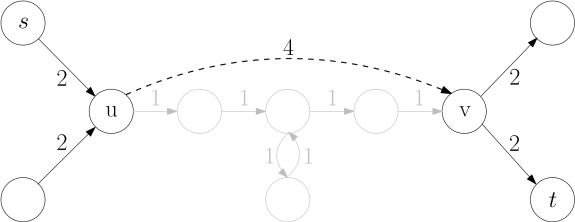
Contraction Heirachies
Generally, contraction hierachies are a speed-up technique for finding the shortest path in a graph. In preprocessing phase, shortcuts are created to skip over “unimportant” vertices. Intuitively, the process is similar to calculating distances for a road network. Distance between two important highway junctions can be pre-computed as a “shortcut” so that the algorithm does not have to consider the full path between the two.
Along the same lines, a Reachability Contraction Hierarchy can be defined based on any number order. We successively “contract” vertices with increasing order, adding shortcuts between pair of vertices that are now disconnected.
The query algorithm uses the ordering and shortcuts as follows: t is reachable from s in the RCH obtained if there is an “up-down” path i.e., a path in which order of vertices has only one maximum. Proof can be found in Section 3.1 of PReaCH.
Summary
Reachability refers to the ability to get from one vertex to another within a graph.
Reachability queries are an interesting problem, improving performance for many graph operations. Better and more sophisticated solutions are being created as the size of working graphs keeps increasing.
Reachability for the undirected graph can be found in linear preprocessing and constant query time with disjoint set unions. The answer isn’t as evident for a directed graph because of differing performance on positive and negative queries, nature and size of the graph, and other factors. Topological levels, Post Order DFS interval, and Contraction Hierarchies are some of the building blocks for such algorithms.
In a later article, I will talk about the specifics of generation number for Git. We will discuss how Git uses reachability queries, the need for Generation Number v2 i.e., Corrected Commit Date With Strictly Monotonic Offset, and other interesting tidbits I came across.
Further Reading
- Reachablity - Wikipedia Page on Reachability. It describes Floyd-Warshal Algorithm, Thorup’s Algorithm, and Kameda’s Algorithm, which can answer queries in constant time with greater preprocessing time or memory use.
- GRAIL - Graph Reachability Interval Labeling uses multiple passes of randomized post order DFS traversals.
- FERRARI - Paper introducing Flexible and Efficient Reachability Range Assignment for gRaph Indexing, which uses approximate intervals with exact intervals to trade off space required by post order DFS for some additional queries.
- PReaCH - Pruned Reachability Contraction Hierarchies. Uses pruning based on topological levels, DFS numbering, and RCH together.